データはどんな「形」をしているのか?——これは統計学の根本的な問いの一つだ。
これまでのカーネル法は「予測」に使ってきた。でも同じアイデアで、 データの確率密度そのものを推定できる。 そしてその密度を使えば、分類問題も解ける。
このページでは、カーネル密度推定(KDE)から出発して、 クラス別密度分類、そして驚くべき性能を持つ「ナイーブベイズ分類器」まで、 一本の流れで理解していく。
このページで学ぶこと:
- カーネル密度推定(KDE)——ヒストグラムを「滑らか」にする
- Parzen推定量——各データ点にガウシアンを被せる方法
- カーネル密度分類——KDEとベイズ定理で事後確率を求める
- ナイーブベイズ分類器——独立仮定で次元の呪いを突破する
- なぜナイーブベイズは「不正確でも強い」のか
データの「形」を知りたい
これまでのカーネル法は「予測」に使ってきた。 ある入力 x があったとき、近くのデータから出力を推定する——その技術だ。
でも、もっと根本的な問いがある。データはどんな形(分布)をしているのか?
例えば、あなたが心臓病リスクの研究者だとしよう。 収縮期血圧のデータが1000件ある。 「このデータは正規分布に従うのか?二峰性か?外れ値はどこにあるか?」 を知りたい——これが密度推定の問いだ。
最も素朴な方法はヒストグラムだ。しかしヒストグラムには欠点がある: 区間の切り方次第で形が変わり、ガタガタして滑らかでない。
カーネル密度推定(KDE)は、このヒストグラムの自然な「滑らか版」だ。 各データ点に小さな山(カーネル)を被せ、全部の山を重ね合わせることで、 滑らかな密度曲線を作る。下のアニメーションで、その仕組みを見てみよう。
 各データ点(青い点)の上にガウス曲線を被せ、重ね合わせた合計(黄色)がKDE密度曲線になる
各データ点(青い点)の上にガウス曲線を被せ、重ね合わせた合計(黄色)がKDE密度曲線になる素朴な推定から始めよう。評価点 x₀ の周辺 λ 幅の近傍に落ちる点を数えるだけ:
$$\hat{f}_X(x_0) = \frac{\#\{x_i \in \mathcal{N}(x_0)\}}{N\lambda}$$
ここで:
- N: データ点の総数(100人のデータなら N=100)
- λ: 窓の幅(血圧で言えば「±10mmHg」など)
- N(x₀): x₀ の近傍に入るデータ点の集合
「この血圧値の周辺に何人いるか」を数える、ただそれだけだ。 問題は区間の端でカクカクすること——次のセクションで、これを滑らかにする方法を見る。
Parzen推定量 — 滑らかな密度を作る
素朴な推定量は「近傍に入るかどうか」を0/1で判断する。 これでは境界でガタつく。
Parzen推定量では、距離に応じた重みを使う。 x₀ から遠い点は小さな重み、近い点は大きな重みを与える:
$$\hat{f}_X(x_0) = \frac{1}{N\lambda} \sum_{i=1}^{N} K_\lambda(x_0, x_i)$$
K_λ はカーネル関数で、x₀ に近いほど大きな重みを与える。 よく使われるのはガウシアンカーネル:
$$K_\lambda(x_0, x) = \phi\!\left(\frac{|x - x_0|}{\lambda}\right)$$
φ は標準正規分布の密度関数(左右対称の鐘型曲線)だ。 これを使うと、推定量は次のように書ける:
$$\hat{f}_X(x) = \frac{1}{N} \sum_{i=1}^{N} \phi_\lambda(x - x_i)$$
全データ点に小さなガウシアンを被せ、N で平均を取る。 各データ点を「点」ではなく「小さな山」として扱うことで、推定が滑らかになる。
数学的には、これは「各データ点に 1/N の重みを置いた分布」をガウシアンでぼかしたものだ。 データをそのまま使うのではなく、各点にわずかなランダムノイズを加えるイメージだ。
 同じデータ点に対して帯域幅λが小さいと詳細(赤)、大きいと滑らか(緑)な密度推定になる
同じデータ点に対して帯域幅λが小さいと詳細(赤)、大きいと滑らか(緑)な密度推定になる帯域幅 λ が鍵だ:
- λ が小さいとき:各データ点の「山」は狭い。 推定はデータに忠実だが、ギザギザになる(高バリアンス)
- λ が大きいとき:各データ点の「山」は広がる。 滑らかになるが、局所的な特徴が失われる(高バイアス)
これはバイアス・バリアンスのトレードオフの 典型例だ。
多次元への自然な拡張もある:
$$\hat{f}_X(x_0) = \frac{1}{N(2\lambda^2\pi)^{p/2}} \sum_{i=1}^{N} e^{-\frac{1}{2}(\|x_i - x_0\|/\lambda)^2}$$
p は次元数。各次元独立にガウシアンを掛けた「球形」のカーネルだ。
密度から分類へ
KDEを手に入れたら、分類問題が解けるようになる。
J クラスの分類問題を考えよう。 各クラス j のデータを使ってクラス条件付き密度 f̂_j(X) を推定する。 クラスの事前確率 π̂_j は、学習データ中の割合(標本比率)で推定する。
ベイズの定理から事後確率が求まる:
$$\hat{\Pr}(G = j \mid X = x_0) = \frac{\hat{\pi}_j \hat{f}_j(x_0)}{\sum_{k=1}^{J} \hat{\pi}_k \hat{f}_k(x_0)}$$
これがカーネル密度分類の基本式だ。 直感的にわかりやすい:
- クラス j の密度が高い場所では、そのクラスに属する確率が高い
- 事前確率 π̂_j で「そもそも各クラスの割合はどれくらいか」を考慮する
- 分母は確率を1に正規化するための定数
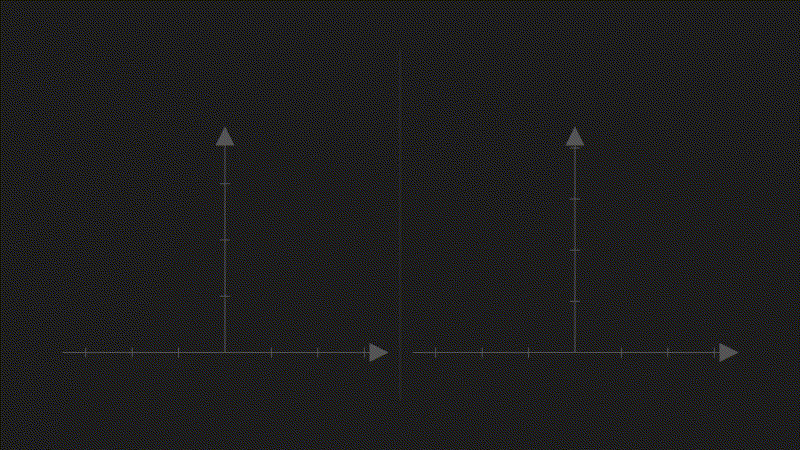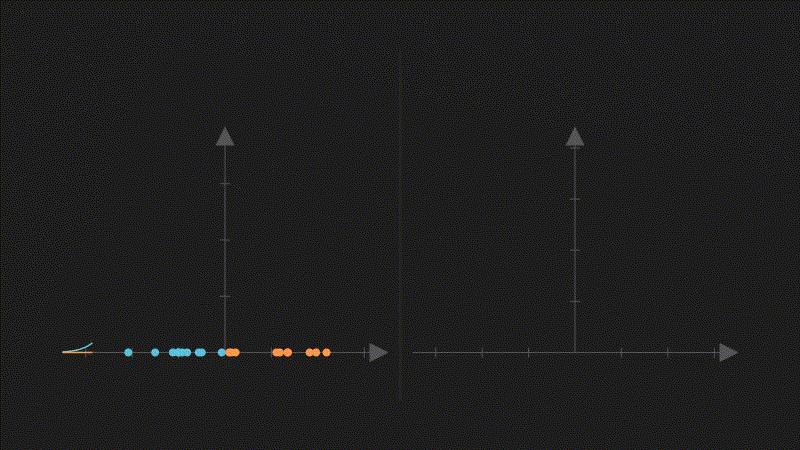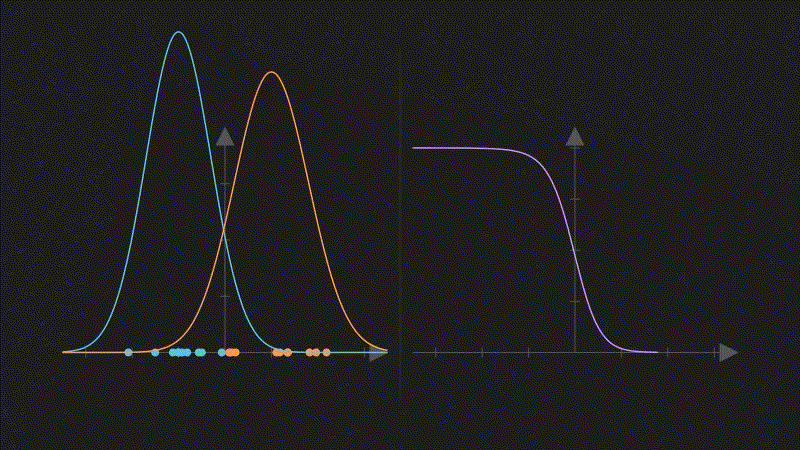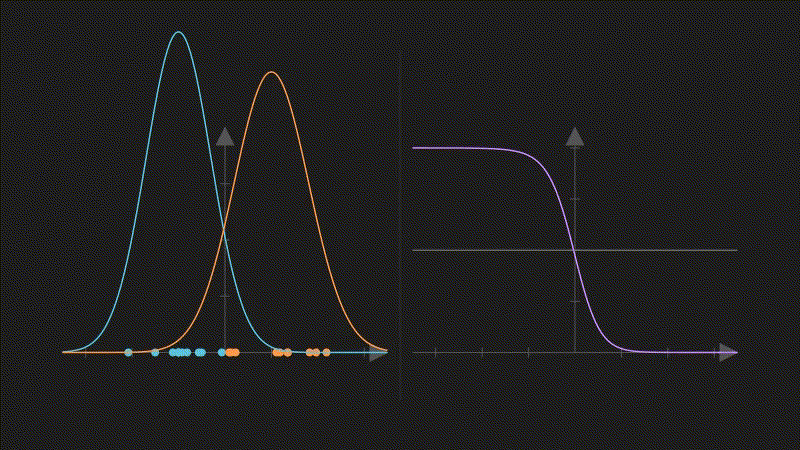 左パネル:クラス別のKDE密度曲線。右パネル:ベイズ定理で計算した事後確率(紫)。水平線は決定境界(0.5)
左パネル:クラス別のKDE密度曲線。右パネル:ベイズ定理で計算した事後確率(紫)。水平線は決定境界(0.5)例えば心臓病(CHD)と健常者の血圧データがあるとする:
- CHDグループの血圧密度 f̂₁(x) を KDE で推定
- 健常者グループの血圧密度 f̂₂(x) を KDE で推定
- ベイズ定理で「この血圧値の人がCHDである確率」を計算
ここで重要な観察がある: 密度推定自体にバイアスがあっても(特に外れ値の多い領域で)、決定境界付近の事後確率は正確に推定できる可能性がある。
目標が分類なら、密度を正確に推定することより、決定境界を正確に推定することが重要だ。 この考え方が次のセクションで重要になる。
ナイーブベイズ — 「素直な」仮定が強力な理由
変数が多い(高次元の)データでは、KDEでクラス密度を直接推定するのが難しくなる。 次元の呪いが再び立ちはだかる——100次元空間のデータを十分に「覆う」には 天文学的な量のデータが必要だ。
ナイーブベイズ分類器は、 この問題を「大胆な仮定」で突破する:
クラス G = j が与えられたとき、特徴量 X₁, X₂, ..., X_p は互いに独立である
この仮定のもとで、クラス条件付き密度が単純な積になる:
$$f_j(X) = \prod_{k=1}^{p} f_{jk}(X_k)$$
ここで f_jk はクラス j における特徴量 X_k の周辺密度(1次元密度)だ。
 上:2次元空間の2クラスデータ(青と橙)と等高線。矢印で分解を示す。下:独立仮定で得られる2つの1次元周辺密度
上:2次元空間の2クラスデータ(青と橙)と等高線。矢印で分解を示す。下:独立仮定で得られる2つの1次元周辺密度この仮定の威力は圧倒的だ:
- 計算量の激減: p 次元の密度推定 → p 個の1次元密度推定
- 柔軟性: 各 f_jk は1次元KDEで推定できる
- 混合型データ: X_k が離散変数なら、ヒストグラム(頻度表)でOK
式の解釈を考えよう。各項の意味:
- j: クラスのインデックス(例: 0=健常者, 1=患者)
- k: 特徴量のインデックス(k=1,...,p、例: 血圧, 年齢, BMI...)
- f_jk: クラス j において特徴量 X_k がどう分布するか
「特徴量が独立なんてあり得ない!血圧と年齢は相関するはず!」 と思うかもしれない。その通り、たいてい成り立たない。 でも、なぜかナイーブベイズは実際に強力に機能する。 その理由を次のセクションで探る。
なぜ「素直な仮定」が強いのか?
独立仮定が明らかに間違っているのに、ナイーブベイズがうまく機能する理由は何か?
鍵は「分類の目標は密度推定ではなく、決定境界の推定」という点にある。
分類で知りたいのは「どちらのクラスか」という境界だ。 「各クラスの密度の形状が正確かどうか」ではない。
「2クラスどちらである確率が高いか」は、確率の比で判断する。 対数をとった確率の比(対数オッズ比)を計算してみよう:
$$\log \frac{\Pr(G=\ell \mid X)}{\Pr(G=J \mid X)} = \alpha_\ell + \sum_{k=1}^{p} g_{\ell k}(X_k)$$
ここで g_ℓk(X_k) = log(f_ℓk(X_k) / f_Jk(X_k)) は、 特徴量 X_k における2クラスの密度比の対数だ。
この式の形に注目しよう。各特徴量 X_k の寄与が独立に加算される: X₁ の寄与 + X₂ の寄与 + ... + X_p の寄与 = 分類スコア。
 左:真の密度(薄い色)とバイアスある推定(濃い色)。右:対応する事後確率。垂直線(決定境界)が両パネルでほぼ同じ位置に現れる
左:真の密度(薄い色)とバイアスある推定(濃い色)。右:対応する事後確率。垂直線(決定境界)が両パネルでほぼ同じ位置に現れるナイーブベイズが強い理由は3つある:
1. バイアスが打ち消される
各クラスの密度推定に同じ方向のバイアスがあっても、 「比」を取ると打ち消される。分子・分母が同じ方向にずれていれば、 比は正確に保たれる。
2. 決定境界が肝心
全体の密度形状が多少ずれても、クラス境界付近の比が正しければ分類は成功する。 密度の細部より境界の位置が重要。
3. バリアンスが低い
p 次元推定の代わりに p 個の1次元推定なので、 データが少なくても安定している。 各1次元推定は少ないデータでも信頼性が高い。
さらに、この対数オッズの式は一般化加法モデル(GAM)の形をしている。 各特徴量 X_k の寄与が独立に加算される構造は、 Chapter 9で詳しく学ぶ一般化加法モデルと同じ構造だ。
この「不正確でも実用的に強い」という現象は、バイアスとバリアンスのトレードオフの 一例だ。完璧な密度推定は難しくても、分類という目標には十分に対処できる。
まとめ — 「カーネル」から「確率」へ
このセクションで学んだことを整理しよう。 3つの手法は共通の思想でつながっている:カーネルを使って局所的に学習し、密度を推定することで分類を行う。
 上段:1次元KDE(単一密度)。中段:2クラスそれぞれのKDE。下段:ナイーブベイズの独立仮定による2D→1D分解
上段:1次元KDE(単一密度)。中段:2クラスそれぞれのKDE。下段:ナイーブベイズの独立仮定による2D→1D分解カーネル密度推定(KDE)
データから確率密度を推定するノンパラメトリック手法
- Parzen推定量: 各データ点にカーネル(例: ガウシアン)を被せ、重ね合わせる
- 帯域幅 λ が鍵: 小さいと詳細(高バリアンス)、大きいと滑らか(高バイアス)
$$\hat{f}_X(x) = \frac{1}{N} \sum_{i=1}^{N} \phi_\lambda(x - x_i)$$
カーネル密度分類
クラス別にKDEを適用し、ベイズ定理で事後確率を計算
- 各クラスの密度を独立に推定
- 事前確率と密度を掛けて正規化
$$\hat{\Pr}(G = j \mid X = x_0) = \frac{\hat{\pi}_j \hat{f}_j(x_0)}{\sum_{k=1}^{J} \hat{\pi}_k \hat{f}_k(x_0)}$$
ナイーブベイズ分類器
高次元問題を独立仮定で解決
- 仮定: クラスが与えられれば特徴量は独立
- 効果: p次元密度推定 → p個の1次元密度推定
- 実用的な強さ: バイアスがあっても決定境界は正確
$$f_j(X) = \prod_{k=1}^{p} f_{jk}(X_k)$$
次のステップ
次の章(6.7: 放射基底関数)では、カーネルを今度は「基底関数」として使うアイデアを探る。 カーネルは密度推定だけでなく、回帰や分類の「表現基底」としても機能する。 ここで学んだKDEの考え方が、より広い文脈でどう活かされるかを見ていこう。